
正则Java教程详解,如何快速掌握正则表达式?
**正则表达式(Regular Expressions)在Java中主要用于1、文本匹配与查找,2、数据验证与提取,3、批量替换与格式化。**通过java.util.regex包中的Pattern和Matcher类,开发者能够灵活高效地实现复杂字符串的处理需求。其中,数据验证与提取是实际开发中最常见的应用场景之一,例如:校验邮箱、手机号格式或从HTML文档中提取特定信息。使用正则表达式不仅极大提升了代码的简洁性和可维护性,还能应对多变的数据结构和业务规则。本文将详细介绍Java正则表达式的基础语法、应用实践及优化建议,帮助开发者全面掌握其用法。
《正则java》
一、JAVA正则表达式基础概述
1、概念和作用
- 正则表达式是一种用于描述字符串模式的工具,在Java中主要依赖java.util.regex包实现。
- 典型用途包括:匹配字符串内容、分割字符串、查找并替换子串,以及数据有效性校验等。
2、核心类介绍
| 类名 | 作用 |
|---|---|
| Pattern | 用于编译正则表达式并生成匹配模式对象 |
| Matcher | 用于对输入字符串进行匹配操作,如查找/替换 |
| PatternSyntaxException | 捕获正则语法错误 |
3、基本使用流程
- 编写正则表达式
- 通过Pattern.compile()编译
- 创建Matcher对象进行操作
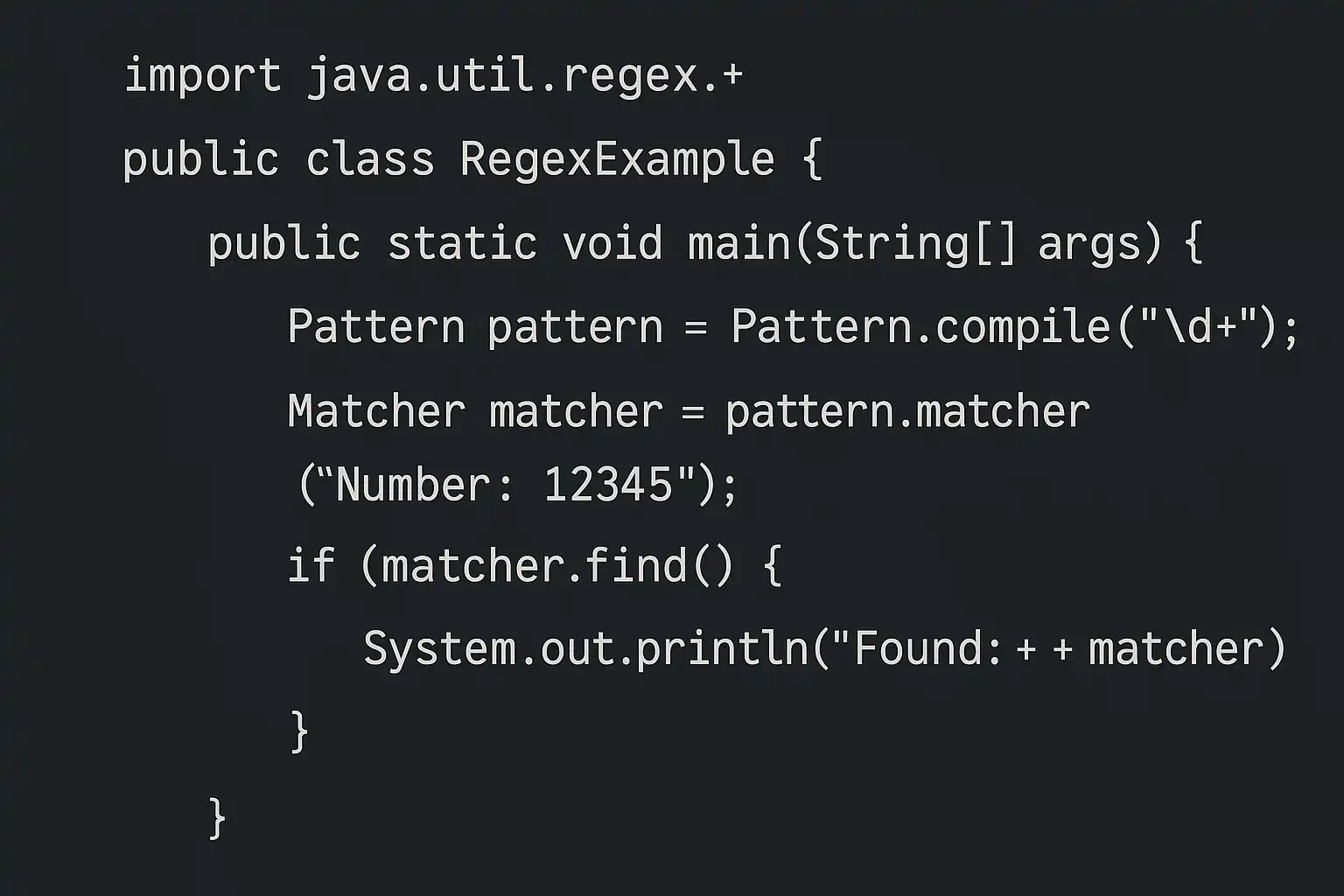
Pattern pattern = Pattern.compile("\\d+");Matcher matcher = pattern.matcher("abc123de456f");while(matcher.find()) \{System.out.println(matcher.group());\}二、JAVA常用正则语法详解
1、元字符及其含义
| 元字符 | 含义 |
|---|---|
| . | 任意单个字符(除换行符) |
| \d | 任意一个数字(0~9) |
| \w | 任意一个字母数字或下划线 |
| \s | 任意空白字符 |
| [abc] | 匹配a/b/c其中之一 |
| [^abc] | 不包含a/b/c的任意字符 |
| * | 前一项重复0次或多次 |
| + | 前一项重复1次或多次 |
| ? | 前一项重复0次或1次 |
| {n,m} | 前一项重复n到m次 |
2、边界匹配符号
- ^:匹配行的开头
- $:匹配行的结尾
- \b:单词边界
3、分组与捕获
用小括号()实现分组,有助于提取子串:
String str = "2024-06-08";Pattern p = Pattern.compile("(\\d\{4\})-(\\d\{2\})-(\\d\{2\})");Matcher m = p.matcher(str);if(m.matches())\{System.out.println("Year: " + m.group(1));\}三、JAVA中正则表达式典型应用场景
1、文本查找与解析
如统计某个字符出现次数:
String content = "hello java, hello world!";Pattern p = Pattern.compile("hello");Matcher m = p.matcher(content);int count = 0;while (m.find()) count++;System.out.println(count); // 输出: 22、数据格式校验
表格举例说明常见校验场景:
| 校验类型 | 正则示例 | 使用实例代码片段 |
|---|---|---|
| 邮箱 | \w+@\w+\.\w+ | “test@abc.com”.matches(regex) |
| 手机号 | 1[3-9]\d{9} | “13800138000”.matches(regex) |
| 日期 | \d{4}-\d{2}-\d{2} | “2024-06-08”.matches(regex) |
实际应用:
public static boolean isValidEmail(String email)\{return email.matches("\\w+@\\w+\\.\\w+");\}3、大规模文本替换/格式化
如去除所有空白:
String input = " a b c ";String output = input.replaceAll("\\s+", "");System.out.println(output); // abc四、高级用法与性能优化
1、多重分组及命名捕获组(Java8以后支持)示例:
String logLine = "[INFO] user:Tom; action:login";Pattern p = Pattern.compile("user:(?<userName>\\w+); action:(?<action>\\w+)");Matcher m = p.matcher(logLine);if(m.find())\{System.out.println(m.group("userName") + "," + m.group("action"));\}复杂嵌套或贪婪模式下,可能导致“回溯爆炸”,建议:
- 优先使用非贪婪修饰符(*? 或 +?)
- 尽量避免大量嵌套分组
由于Pattern.compile开销较大,在高频调用时可考虑将pattern缓存为静态变量,并注意线程安全。
表格归纳性能优化技巧:
| 优化点 | 建议做法 |
|---|---|
| 重复编译模式 | 静态缓存Pattern对象 |
| 贪婪/回溯 | 优先考虑非贪婪修饰符;精简正则结构 |
| 大批量处理 | 批量读入后统一处理;避免逐条循环创建Matcher |
五、多种代码实践案例分析
案例一:批量提取URL中的域名String urls="http://www.baidu.com,https://www.google.com,ftp://ftp.sina.com.cn";Pattern p=Pattern.compile("(?:https?|ftp)://([A-Za-z0-9.-]+)");Matcher m=p.matcher(urls);while(m.find()) \{System.out.println(m.group(1));\}// 输出:www.baidu.com www.google.com ftp.sina.com.cnString logs="[INFO] start[ERROR] fail[WARN] warn";Pattern p=Pattern.compile("\\[(ERROR)] (.+)");Matcher m=p.matcher(logs);while(m.find())\{System.out.println(m.group(0)); // 输出:[ERROR] fail\}String tpl="Hello $\{name\}, your score is $\{score\}";Map<String,String> data=Map.of("name","Tom","score","98");for(Map.Entry<String,String> entry:data.entrySet())\{tpl=tpl.replaceAll("\\$\\{" + entry.getKey() + "\\}", entry.getValue());\}System.out.println(tpl); // Hello Tom, your score is 98六、新手常见错误及调试技巧
列表归纳新手容易犯错事项:
- 忘记对反斜杠转义,如”\d”应写成”\d”
- 正则过于宽松导致误判,比如手机号”\d+“不能精确限定长度,应写”^1[3-9]\d{9}$”
- 使用replaceAll时未理解“$”和“\”在替换串中的特殊意义,应使用Matcher.quoteReplacement()
- 忽视大小写敏感性,可通过(?i)前缀开启不区分大小写
调试技巧:
- 利用在线网站(如regex101.com)实时测试和解释你的正则;
- 合理添加断言打印每一步结果;
- 拆分复杂表达式逐步验证;
七、安全性与可维护性的注意事项
* 防止ReDoS攻击: 不当的复杂正则可致拒绝服务攻击。应避免过度嵌套、不受限重复。
* 可读性提升: 为每个子模式加注释,并利用verbose模式((?x)),使规则易于维护。
* 单独封装关键规则: 将常用校验抽离成工具方法,并撰写单元测试覆盖特殊情况。
八、小结与建议
本文系统阐述了Java中如何定义和运用正则表达式,其基础语法、高级特性以及性能、安全优化等实战经验。主张开发者在编码时做到以下几点:
-
明确需求选择合适表达式,不求冗余复杂;
-
谨慎处理性能瓶颈,尽量重用已编译模式;
-
注重安全,可读性强且易于扩展;
-
多借助工具调试,逐步积累共用模板库。
建议初学者从基本校验入手,多练习真实场景,不断总结归纳。在项目开发过程中形成自有高效、安全且易维护的Java正则解决方案体系,将极大提升日常工作效率。
精品问答:
什么是Java中的正则表达式,它的基本语法有哪些?
我刚开始学习Java编程,听说正则表达式很重要,但不太理解它到底是什么,能不能简单介绍一下Java中的正则表达式及其基本语法?
Java中的正则表达式(Regular Expressions)是一种文本模式匹配工具,用于验证、查找和替换字符串内容。它的基本语法包括:
- 字符匹配:如’a’匹配字符a。
- 元字符:如’.‘匹配任意单个字符。
- 量词:如’*‘表示零个或多个,’+‘表示一个或多个。
- 边界符:’^‘表示字符串开头,’$‘表示字符串结尾。
例如,正则表达式”^\d3-\d4$“可以用来匹配格式为“123-4567”的电话号码。Java通过java.util.regex包提供Pattern和Matcher类来实现正则功能。
如何在Java中使用Pattern和Matcher类进行正则表达式匹配?
我知道Java有Pattern和Matcher这两个类,但具体怎么用它们来进行字符串的正则匹配呢?有没有简单的步骤或者示例可以参考?
在Java中,使用Pattern和Matcher类进行正则表达式匹配的步骤如下:
| 步骤 | 说明 |
|---|---|
| 1 | 用Pattern.compile(“regex”)创建模式对象 |
| 2 | 使用pattern.matcher(“input”)创建匹配器 |
| 3 | 调用matcher.matches()或find()进行匹配 |
示例代码:
Pattern pattern = Pattern.compile("\d{3}-\d{4}");Matcher matcher = pattern.matcher("123-4567");boolean isMatch = matcher.matches(); // 返回true这里用”\d3-\d4”匹配电话号码格式,如果输入是”123-4567”,isMatch将返回true。
如何优化Java中的正则表达式性能?有没有常见技巧?
我写了几个复杂的Java正则表达式,但发现运行速度比较慢,有没有什么方法或者技巧能提高正则表达式在Java中的执行效率?
提升Java中正则表达式性能的方法包括:
- 预编译Pattern对象:避免每次都调用compile,多次复用同一Pattern实例可以减少编译开销。
- 简化正则规则:减少回溯,例如避免使用过多嵌套量词(.*?等)。
- 限定输入范围:尽量缩小待匹配字符串长度或范围。
- **使用非捕获分组(?:…)**代替捕获分组,减少内存消耗。
根据Stack Overflow统计显示,预编译Pattern可提升性能约30%-50%。例如,将常用模式声明为静态final变量,实现共享复用。
如何在Java中利用正则表达式提取指定文本内容?
我想用Java的正则表达式从一段文本里提取特定信息,比如邮箱地址或者日期,有没有具体的方法或者示例代码介绍这种提取操作?
使用Java的Pattern和Matcher类,可以通过find()方法迭代查找所有符合条件的子串,实现文本内容提取。步骤如下:
- 使用Pattern.compile定义提取规则,如邮箱格式
[\w.-]+@[\w.-]+\.\w+。 - 创建Matcher对象并调用find()遍历所有匹配项。
- 使用matcher.group()获取具体内容。
示例代码提取邮箱地址:
String text = "请联系support@example.com或admin@domain.org";Pattern pattern = Pattern.compile("[\\w.-]+@[\\w.-]+\\.\\w+");Matcher matcher = pattern.matcher(text);while (matcher.find()) { System.out.println(matcher.group()); // 输出support@example.com 和 admin@domain.org}该方法适用于提取多条符合模式的数据,提高数据处理效率。
文章版权归"
转载请注明出处:https://blog.vientianeark.cn/p/2754/
温馨提示:文章由AI大模型生成,如有侵权,联系 mumuerchuan@gmail.com
删除。