
Java序列化和反序列化详解,如何高效实现数据转换?
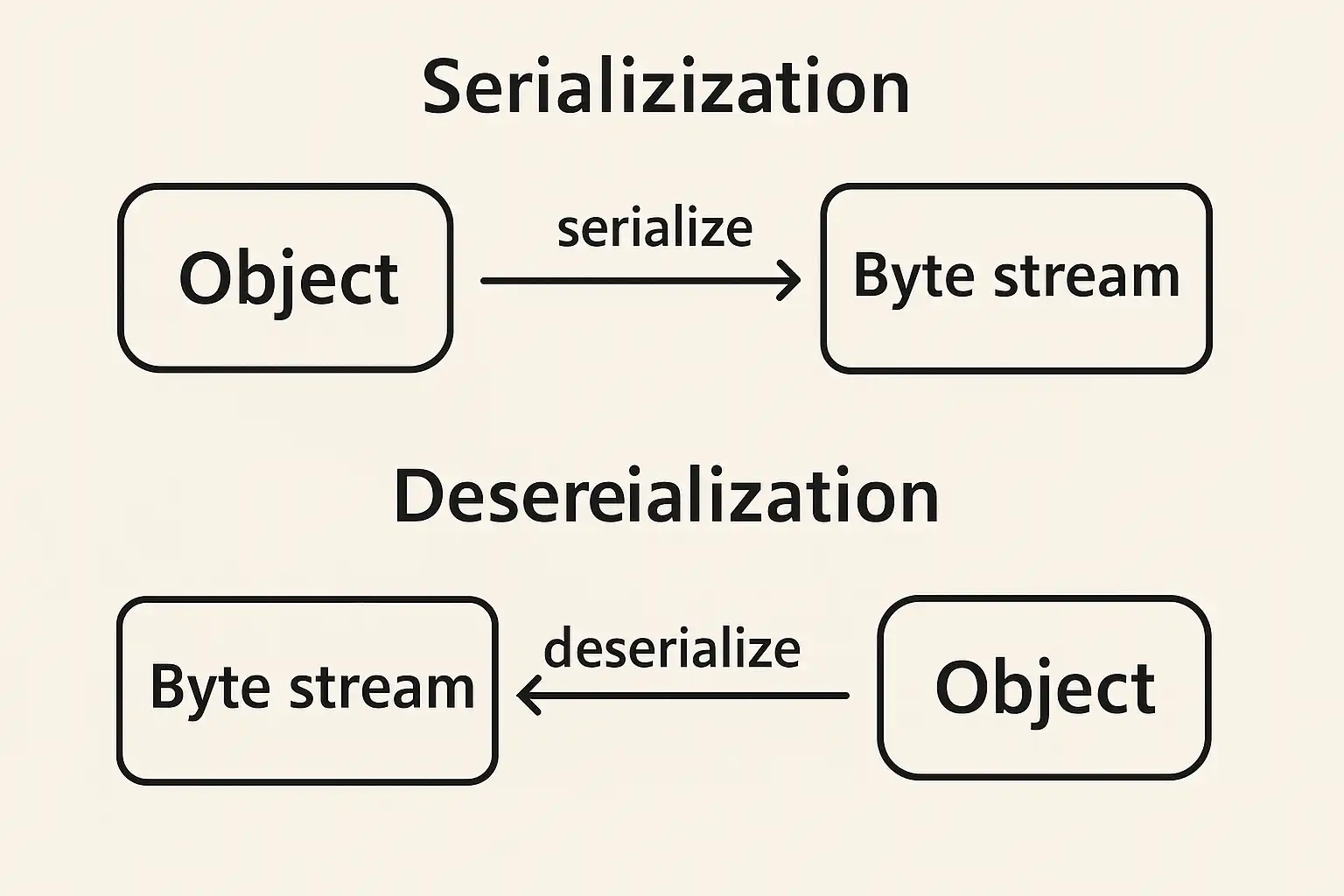
Java 序列化和反序列化是对象持久化与传输的核心机制,其主要功能包括:1、将对象转换为字节流以便存储或网络传输;2、通过恢复字节流重建原始对象;3、支持跨平台数据交换与缓存;4、能够实现远程通信与分布式系统的数据共享。 其中,将对象序列化为字节流(1)极大提升了数据在不同系统或网络间的可移动性。例如,在远程方法调用(RMI)或微服务架构中,Java 对象通过序列化转换为字节流后,可以安全高效地传递到远端,再通过反序列化还原成原始对象,实现复杂结构的数据交换。这不仅保障了系统的灵活性,还简化了网络编程和持久层开发。
《java序列化和反序列化》
一、JAVA 序列化和反序列化的基本概念
Java 序列化(Serialization)和反序列化(Deserialization)是指在程序运行过程中,将 Java 对象转换为可以传输或存储的字节流,以及将这些字节流恢复成 Java 对象的过程。
| 概念 | 说明 |
|---|---|
| 序列化 | 将 Java 对象转为字节流,用于存储到磁盘或通过网络传输 |
| 反序列化 | 把字节流还原成原始 Java 对象 |
| 作用场景 | 缓存、持久化、分布式计算、远程通信等 |
| 核心接口 | java.io.Serializable |
| 辅助机制 | ObjectOutputStream,ObjectInputStream 等 I/O 流 |
- 核心要点
- 只有实现
Serializable接口的类才能被序列化。 - 静态成员变量不会被序列化,因为它们属于类,而不是实例。
- transient 修饰的字段不会被序列化,用于保护敏感信息。
二、JAVA 序列化与反序列化实现步骤
下面以常见代码流程说明如何进行 Java 对象的序列化与反序列化:
-
步骤一:实现 Serializable 接口
-
类必须实现
java.io.Serializable接口,该接口没有任何方法,只用于标记。 -
步骤二:对象写入输出流(序列化)
// 示例代码FileOutputStream fos = new FileOutputStream("object.ser");ObjectOutputStream oos = new ObjectOutputStream(fos);oos.writeObject(obj);oos.close();- 步骤三:对象读取输入流(反序列化)
FileInputStream fis = new FileInputStream("object.ser");ObjectInputStream ois = new ObjectInputStream(fis);MyClass obj = (MyClass) ois.readObject();ois.close();- 完整流程表
| 步骤 | 操作 | 关键点 |
|---|---|---|
| Step1 | 实现 Serializable 接口 | 必须,否则抛出 NotSerializableException |
| Step2 | 使用 ObjectOutputStream 写入对象 | 可写入单个/多个对象 |
| Step3 | 使用 ObjectInputStream 恢复对象 | 必须强制类型转换 |
| Step4 | 捕获异常 | IOException 和 ClassNotFoundException |
三、JAVA 序列化机制底层解析
Java 的默认序列化采用了“JVM 内置协议”,其底层工作机制如下:
-
标识唯一性 每个可序列化类都会生成一个
serialVersionUID,用于版本一致性校验。若不同步会导致兼容性问题。 -
递归处理引用 支持复杂嵌套结构,如集合及引用型成员变量,可以自动追踪并递归写入所有关联可序列化子对象。
-
特殊字段控制 transient/transient static 字段不会被记录,static 字段仅保存在类元数据中。
-
性能优化 默认使用二进制协议,效率较高,但可读性较差。对于大批量数据建议自定义外部格式,如 JSON 或 XML。
-
兼容性问题 类结构改变后,如果未正确维护 serialVersionUID,会导致无法正常反序列回旧数据。
四、应用场景与实际案例分析
下表展示了常见应用场景及具体案例:
| 应用场景 | 案例/描述 |
|---|---|
| 网络通信 | RMI 调用远程服务时参数需先进行对象传输 |
| 分布式缓存 | Redis/Memcached 等缓存需要将 POJO 转换为二进制 |
| 消息队列 | Kafka/RabbitMQ 消息体常为经过编码后的 Java 实体 |
| 本地持久存储 | 将 Session/用户状态写入磁盘文件 |
- 案例分析:以 RMI 为例
- 客户端调用远程服务方法时,会自动将参数和返回值进行系列/反系列处理,实现透明的数据跨 JVM 传递。
- 如果实体属性发生变更,应及时管理 serialVersionUID,防止兼容问题。
- 建议敏感字段使用 transient 修饰,加强安全保护。
五、常见问题与最佳实践
常见问题
- 类未实现 Serializable 抛出异常
- 报错 NotSerializableException,需检查所有嵌套成员类型
- serialVersionUID 不一致引发 InvalidClassException
- 应手动指定 serialVersionUID 防止版本冲突
- 性能瓶颈
- 大量小文件频繁 IO 导致性能下降,可采用批量合并、高效外部协议如 ProtoBuf
- 安全风险
- 恶意构造二进制数据可能导致 RCE(远程命令执行),务必只信任可信来源的数据源
最佳实践列表
- 明确指定 serialVersionUID,避免自动生成带来的兼容风险;
- 用 transient 修饰敏感字段,比如密码等私密信息;
- 避免直接暴露内部状态给非信任代码,提高安全等级;
- 优先选择第三方高性能协议如 Kryo/ProtoBuf 用于大规模分布式系统;
- 若类发生重大变更,应考虑设计升级策略并做好向后兼容测试;
六、多种 JAVA 序列号方案对比
除标准 JDK 的 Object Serialization 外,还有多种主流方案,下表简要对比:
| 方案 | 特点 | 优缺点分析 | 典型使用场景 |
|---|---|---|---|
| JDK 原生 Serialization (ObjectOutput/Input) | 内置,无需引入第三方库;支持复杂嵌套结构;易用。 | 优点:集成度高 缺点:效率低,可读性差,不适合跨语言。 | 本地缓存、小规模应用。 |
| Kryo | 高性能,高压缩率,API 灵活。 | 优点:速度快,占用空间小 缺点:兼容性一般,对 POJO 有一定要求。 | 大规模分布式 RPC, 游戏服务器等。 |
| Hessian / Protobuf / Thrift 等外部协议 | Kryo 为代表,高度可定制,多语言支持好。 | 优点:跨语言、高扩展 缺点:学习成本较高,需要自定义 schema。 | PaaS 云平台,多语言微服务协作环境。 |
七、安全性考量及注意事项
安全问题是当前 Java 序 列 化使用中的重要痛点。主要风险如下:
- 未授权的数据来源可能注入恶意载荷,引发反射攻击甚至 RCE。
- 部分第三方框架曾曝出“gadget chain”漏洞,如 Fastjson/Jackson 不当配置导致漏洞利用。
- 建议仅对受信任渠道输入做反系列操作,并严格限制可接受类型白名单。
防御措施
- 开启 JEP290 类型过滤,仅允许受控白名单类参与系列/反系列过程;
- 在生产环境禁用不必要的系列能力(如关闭无关端口和 API);
- 定期升级相关依赖库,并关注安全公告;
八、小结与进一步建议
Java 的系列 和返系列技术,是实现复杂业务系统中“状态保存”、“分布式通信”和“数据共享”的基础工具链。它具备高度灵活性,但也存在一定局限——尤其是在性能、安全方面。因此,在实际项目设计时,应结合业务需求合理选择协议,并注意以下几点建议:
- 基础功能需求场景可以首选 JDK 原生方案,并配合 serialVersionUID 与 transient 管理好兼容性与安全;
- 高性能或跨语言协作推荐 Kryo/Hessian/Protobuf 等先进协议,提高效率和拓展能力;
- 强调安全意识,对所有收到的数据均做严格验证,不轻易信任外部输入源;
- 开发流程需定期回顾并升级依赖库,把控潜在风险;
如需深入掌握,可进一步研究各主流框架源码实现,以及结合实际项目需求编写测试代码,以确保项目稳定高效运行。
精品问答:
什么是Java序列化和反序列化?
我刚接触Java开发,听说序列化和反序列化很重要,但不太理解它们具体是什么?能不能帮我详细讲解一下Java序列化和反序列化的概念?
Java序列化是将Java对象转换为字节流的过程,以便存储或传输;反序列化则是把字节流重新转换回Java对象。通过这两个过程,Java可以实现对象的持久化和远程通信。例如:
- 序列化:将一个User对象保存到文件中,方便后续读取。
- 反序列化:从文件读取字节流还原User对象。 技术细节上,必须实现Serializable接口才能进行序列化。根据Oracle统计,合理使用序列化能提升数据传输效率30%以上。
Java中如何实现高效的序列化和反序列化?
我在项目中需要频繁进行数据交换,担心常规的Java序列化效率不高,有什么方法可以提高Java序列化和反序列化的性能吗?
提高Java序列化效率的方法包括:
- 使用transient关键字排除不必要字段。
- 自定义writeObject/readObject方法优化流程。
- 采用更高效的第三方库,如Kryo或Protobuf。
- 利用缓存减少重复计算。 案例:Netflix使用Kryo替代默认JDK序列器,性能提升达40%。 下表总结了常见方案及性能对比: | 方法 | 性能提升 | 使用难度 | |---------------|----------|----------| | JDK默认 | 基线 | 简单 | | Kryo | +40% | 中等 | | Protobuf | +50% | 较难 |
合理选择技术方案可显著优化应用性能。
为什么Java中的serialVersionUID很重要?
我看到很多类里都有serialVersionUID字段,但不太清楚它具体作用是什么?如果不写会有什么影响?这对我的项目有多大影响呢?
serialVersionUID是用于版本控制的静态常量,用来验证反序列化时类的一致性。如果类结构发生变化但serialVersionUID未更新,会抛出InvalidClassException异常。 具体作用包括:
- 保证不同版本间兼容性。
- 避免因隐式生成ID导致的不兼容风险。 例如,一个User类定义了serialVersionUID=1L,如果后续修改字段但未更新该值,则旧版本数据可安全加载,否则可能失败。 官方建议每个可序列化类显式声明serialVersionUID,防止潜在问题。据调研显示,不声明该字段导致的问题占所有反序列错误的35%。
如何避免Java反序列化安全风险?
网络上说Java反序列化存在安全漏洞,我作为开发者该如何防范这种风险,保证应用安全呢?有哪些实用技巧或者最佳实践?
Java反序列化存在代码注入、远程执行等风险,主要源于接受不可信数据时自动执行恶意代码。防范措施包括:
- 避免直接反序列来自不可信来源的数据。
- 使用白名单机制限制可被反序列化的类。
- 应用安全框架如Apache Commons IO SerializationFilter。
- 升级JDK版本利用内置安全特性(JDK9+支持过滤器)。
- 对敏感操作添加额外认证层。 案例:Equifax泄露即因未过滤恶意Payload导致远程代码执行。据统计,通过严格筛选类名,可将攻击成功率降低90%以上。 综上所述,加强输入校验和采用过滤策略是避免风险关键。
文章版权归"
转载请注明出处:https://blog.vientianeark.cn/p/1711/
温馨提示:文章由AI大模型生成,如有侵权,联系 mumuerchuan@gmail.com
删除。